According to Simon Guest from Microsoft on their cloud computing architecture. Although there was no new concept or idea introduced, Simon has provided an excellent summary on the major patterns of doing cloud computing.
I have to admit that I am not familiar with Azure and this is my first time hearing a Microsoft cloud computing presentation. I felt Microsoft has explained their Azure platform in a very comprehensible way. I am quite impressed.
Simon talked about 5 patterns of Cloud computing. Let me summarize it (and mix-in a lot of my own thoughts) …
1. Use Cloud for Scaling
The key idea is to spin up and down machine resources according to workload so the user only pay for the actual usage. There is two types of access patterns: passive listener model and active worker model.
Passive listener model uses a synchronous communication pattern where the client pushes request to the server and synchronously wait for the processing result.
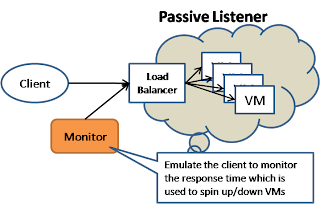

In the passive listener model, machine instances are typically sit behind a load balancer. To scale the resource according to the work load, we can use a monitor service that send NULL client request and use the measured response time to spin up and down the size of the machine resources.
On the other hand, Active worker model uses an asynchronous communication patterns where the client put the request to a queue, which will be periodically polled by the server. After queuing the request, the client will do some other work and come back later to pickup the result. The client can also provide a callback address where the server can push the result into after the processing is done.
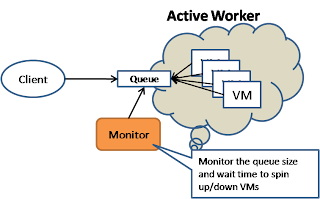

In the active worker model, the monitor can measure the number of requests sitting in the queue and use that to determine whether machine instances (at the consuming end) need to be spin up or down.
2. Use Cloud for Multi-tenancy
Multi-tenancy is more a SaaS provider (rather than an enterprise) usage scenario. The key idea is to use the same set of code / software to host the application for different customers (tenants) who may have slightly different requirement in
- UI branding
- Business rules for decision criteria
- Data schema
The approach is to provide sufficient “customization” capability for their customer. The most challenging part is to determine which aspects should be opened for customization and which shouldn’t. After identifying these configurable parameters, it is straightforward to define configuration metadata to capture that.
3. Use Cloud for Batch processing
This is about running things like statistics computation, report generation, machine learning, analytics … etc. These task is done in batch mode and so it is more economical to use the “pay as you go” model. On the other hand, batch processing has very high tolerance in latency and so is a perfect candidate of running in the cloud.
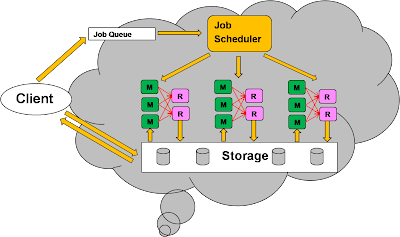

Here is an example of how to run Map/Reduce framework in the cloud. Microsoft hasn’t provided a Map/Reduce solution at this moment but Simon mentioned that Dryad in Microsoft research may be a future Microsoft solution. Interestingly, Simon also recommended Hadoop.
Of course, one challenge is how to move the data from the cloud in the first place. In my earlier blog, I have describe some best practices on this.
4. Use Cloud for Storage
The idea of storing data into the cloud and no need to worry about DBA tasks. Most cloud vendor provide large scale key/value store as well as RDBMS services. Their data storage services will also take care of data partitioning, replication … etc. Building cloud storage is a big topic involving many distributed computing concepts and techniques, I have covered it in a separate blog.
5. Use Cloud for Communication
A queue (or mailbox) service provide a mechanism for different machines to communicate in an asynchronous manner via message passing.
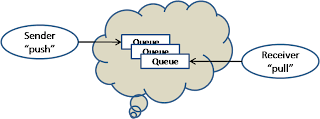
Azure also provide a relay service in the cloud which is quite useful for machines behind different firewall to communicate. In a typical firewall setup, incoming connection is not allowed so these machine cannot directly establish a socket to each other. In order for them to communicate, each need to open an on-going socket connection to the cloud relay, which will route traffic between these connections.

Azure also provide a relay service in the cloud which is quite useful for machines behind different firewall to communicate. In a typical firewall setup, incoming connection is not allowed so these machine cannot directly establish a socket to each other. In order for them to communicate, each need to open an on-going socket connection to the cloud relay, which will route traffic between these connections.

I have used the same technique in a previous P2P project where user’s PC behind their firewall need to communicate, and I know this relay approach works very well.